This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The text fule will be automatically downloaded. Once done, a text file will be automatically downloaded to your computer. Searchability: Word documents are searchable, making locating specific information within the text easier, whereas finding details within an image can be challenging and time-consuming. That’s it.
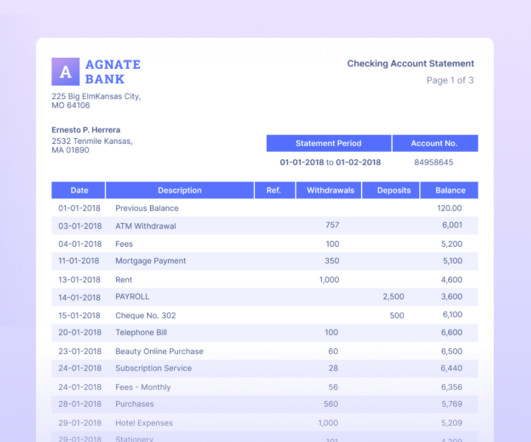
Manual entry of data from these statements into the central database is time-consuming and error-prone. Nanonets’ PDF scraper OCR is particularly useful for converting bank statements into machine-readable structured data formats such as excel files (CVS, XML, JSON etc.).
However there is one difference: FedNow is primarily targeted at banks – not at consumers. In this case, bragging about ‘adoption’ is like a fintech bragging about how about many people have downloaded their app (ignoring—or glossing over—the actual # of people who use the app).” It’s a tough choice.
Doing this manually would be extremely time-consuming and error-prone. While this method is the simplest, it is also the most time-consuming and error-prone. These tools can also not be automated and have the manual element of having to navigate to each page that needs to be extracted making them time consuming. #3.
Let's say you need a patient's information; then, searching for them from thousands of PDFs will be very hectic and time-consuming. Download your PDF file automatically. This process is very time-consuming, which is why it is not preferred in big organizations where there are tons of files to look for.
While this method is the simplest, it is also the most time-consuming and error-prone. Scrape data from website to Excel with Nanonets Step 2 : Click on 'Scrape and Download' Click on Scrape and Download to start web scraping Step 3 : Once done, the tool downloads the Excel file with the scraped website data automatically.
Manual data entry is time-consuming and prone to errors, especially as transaction volumes grow. By automating time-consuming tasks, AI tools free up valuable resources, allowing employees to focus on strategic decision-making rather than data processing.
However, converting PDF to Excel manually or without tools is time-consuming, error-prone, and not a very productive way to convert data. After a few seconds, your Excel file will be automatically downloaded. PDFs are great for sharing or view the data but not for analyzing the data. That's where PDF to Excel converters come in.
For example, processing vendor contracts and extracting key terms and clauses from hundreds of PDFs can be tedious and time-consuming. Download the output file containing the extracted text and copy the required text. It may not be ideal for bulk text extraction from PDFs. Scanned pages are even more difficult to copy text from.
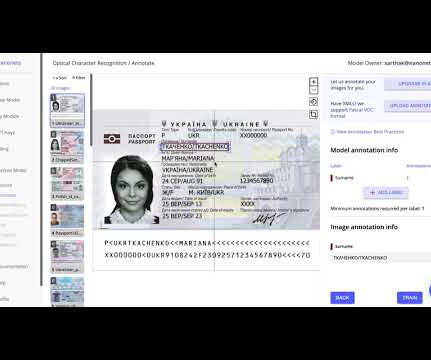
Manual processing of forms is time-consuming and error-prone, which is why businesses are increasingly turning to OCR technology for a more efficient and accurate process. Manual Form Processing has a lot of drawbacks - Time-consuming : Manual form processing can be a time-consuming task, especially when dealing with a large number of forms.
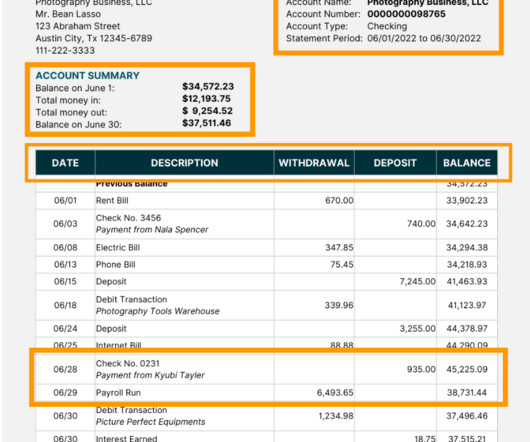
Traditional manual processing and reconciling, which consumes an average of 10-12 hours per week , is no longer an option. This process is critical for companies with high transaction volumes, where manual reconciliation is time-consuming and error-prone.
This manual process is not only time-consuming but also prone to errors. You can also download the structured outputs (CSV, JSON, XML) for further analysis or use webhooks or Zapier to push the data to other systems in real time. To do this, you can simply set up the relevant data export rules.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content