This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Portable Document Format (PDF) is the go to file format for sharing & exchanging business data. In other document formats such as DOC, XLS or CSV, extracting a portion of information is pretty simple. But this is quite challenging to do in the case of PDFs. You can view, save and print PDF files with ease.
Introduction XML stands for Extensible Markup Language and is one of the more popular formats in which data is stored and shared between systems and software. XML is a versatile coding language similar to HTML. Today, PDF documents are widely used across organizations. Looking to convert PDF to XML ?
This makes it hard to keep track of documents and identify them. Precious man-hours are spent in renaming and organizing such documents for convenient reference. This allows users to identify files more quickly, and get some information about the documents without having to open them individually.
Giphy Organisational workflows today largely depend on searchable PDF documents; especially those that contain lots of tabular data. Most data-rich business documentsuse tables to organise & present valuable information. Businesses often look for solutions to extract the tabular PDF data as editable table formats.
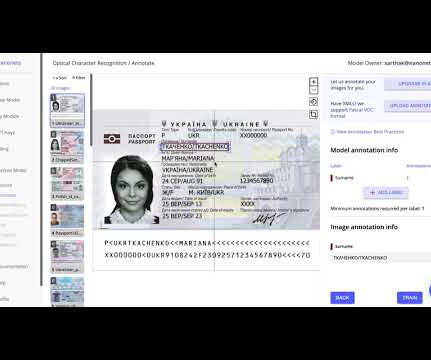
Optical character recognition (OCR) software help convert non-editable document formats such as PDFs, images or paper documents into machine-readable formats that are editable & searchable. OCR is also used to digitise files and documents to make them searchable.
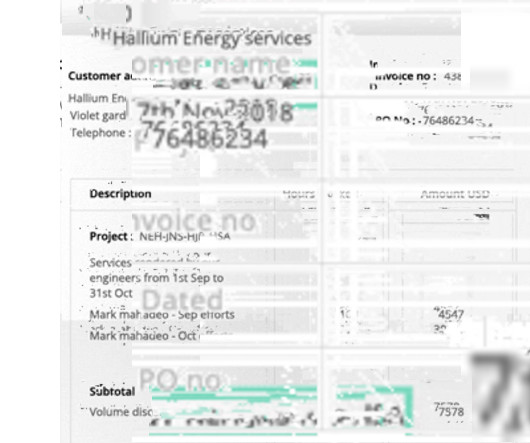
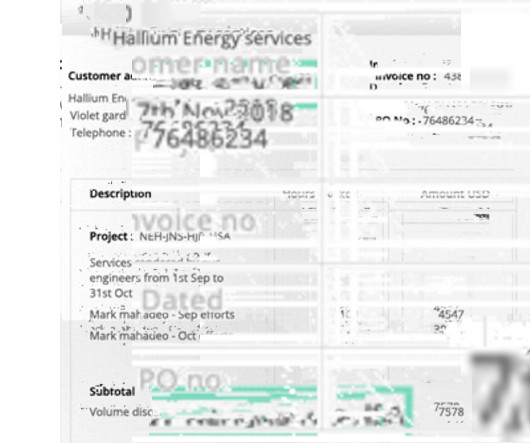
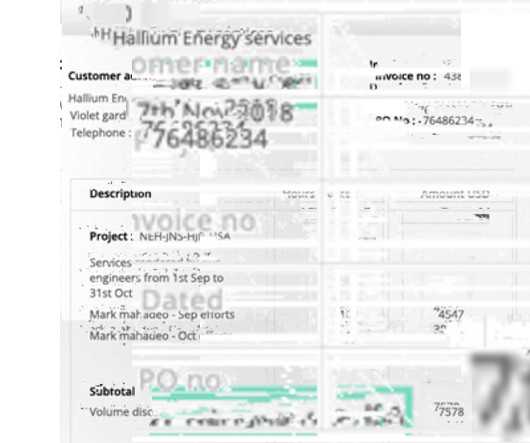
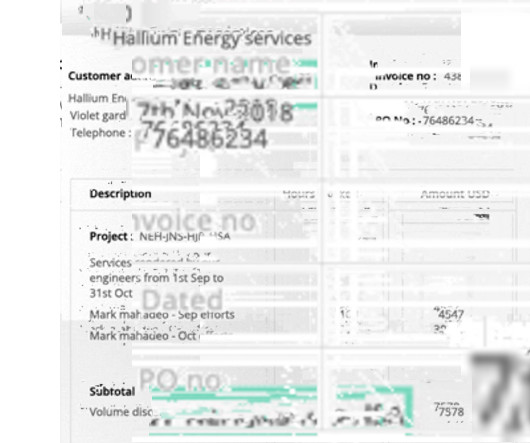
PDF → Excel Convert PDF bank statements to Excel Try for Free The digitization of financial documents is an important task for financial institutions like banks as well as individual banking customers and businesses. To understand how Bank Statement OCR can be used, it is important to understand the contents of a bank statement.
Optical character recognition (OCR) software help convert non-editable document formats such as PDFs, images, or paper documents into machine-readable formats that are editable & searchable. OCR is also used to digitise files and documents to make them searchable. Reduce turnaround times and eliminate manual effort.
Optical character recognition (OCR) software help convert non-editable document formats such as PDFs, images, or paper documents into machine-readable formats that are editable & searchable. OCR is also used to digitise files and documents to make them searchable. We will also check out some free OCR software.
Optical character recognition (OCR) software help convert non-editable document formats such as PDFs, images, or paper documents into machine-readable formats that are editable & searchable. OCR is also used to digitise files and documents to make them searchable. We will also check out some free OCR software.
Today, PDF documents have become a standard format for sharing and preserving information across all organizations. Method 1: Copy and Paste The simplest and most common method to extract text from a PDF file is to use the copy-and-paste functionality. There are multiple ways in which text can be extracted from PDF files.
Snapping or clicking an image is the easiest way to capture text from paper documents conveniently in your phone or computer. Add or drop the image into a Word document. Microsoft Word will automatically detect the text in the PDF and display it as editable text on the new Word document created in step 3.
OCR (Optical Character Recognition) is a game changer for anyone who works with PDF documents. As an industry leader in PDF software, Adobe packs Acrobat Pro with advanced OCR capabilities that easily handle complex documents. You can OCR a documentusing Acrobat Pro in two ways: Method 1 Open the PDF file in Adobe Acrobat Pro.
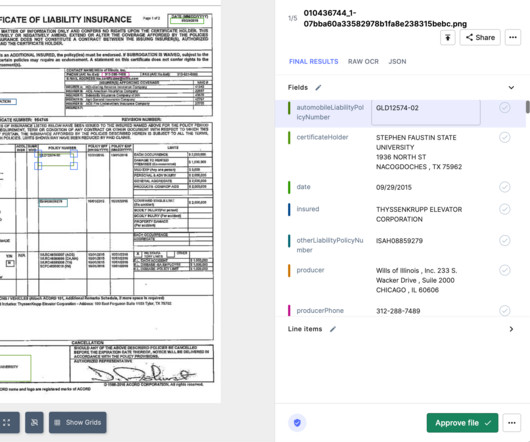
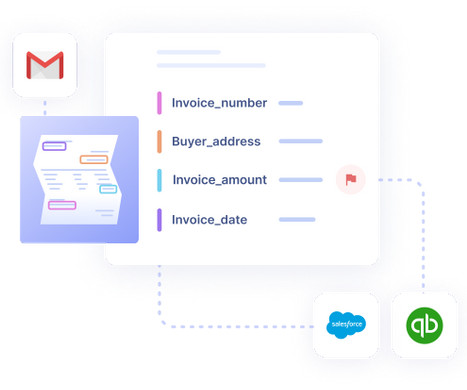
It allows them to automate the extraction and interpretation of text from images, invoices, receipts, and other documents. These cutting-edge solutions transform how businesses handle their financial documents and set new standards for accuracy, speed, and overall productivity.
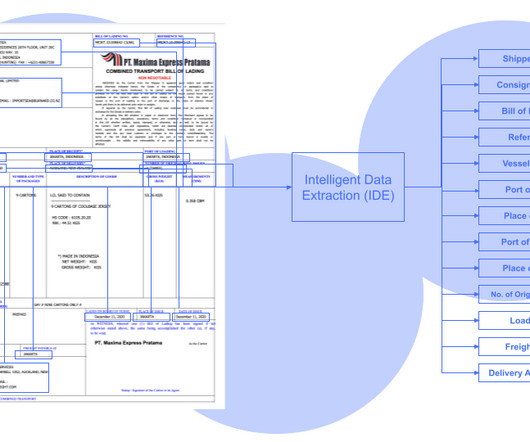
Organisations have vast oceans of information, from invoices and purchase orders to customer forms and legal documents. Intelligent Data Extraction is an automated process of accurately identifying and extracting relevant data points from documents leveraging modern-day technology. Data is the life of business operations.
At the same time, a large number of companies have also started using Google Sheets integrations to automate tasks. Convert PDF to Google Sheets Let’s consider a typical usecase: Your Accounts Payable team receives an invoice, in the standard PDF format. Let’s try opening the same PDF documentusing a text editor.
If you have ever copied and pasted data from any website into an Excel spreadsheet or a Word document, essentially, it is web scraping at a very small scale. The copy-paste method is useful when web scraping needs to be done for personal projects or one-time usecases. This method is best for a one-time usecase.
In this blog, we will discuss some of the most common usecases of market research and how web scraping can aid in getting accurate market insights quickly. With the help of web scraping, this market research usecase can be completed much more quickly while attaining data at a much higher level of accuracy.
These documents are often lengthy—sometimes running over 100 pages—making it challenging to grasp the key points quickly. Lease abstraction is a critical process in the real estate and property management industries, involving the extraction of key information from lengthy and complex lease documents.
Companies use website scraping tools to extract lead information from a website and then push this data into their CRM system. Sales and marketing teams can then use this information to reach out to prospective clients. The information that is scraped is dependent on the business usecase.
Here's a snapshot of our recommendations: Best for Data extraction From Documents - Nanonets Best for Web scraping for e-commerce - Import.io Data extraction can refer to scraping information from web pages or emails but includes any other type of text-based file such as spreadsheets (Excel), documents (Word), XML , PDFs, etc.
With automation, insurers can automate repetitive tasks such as manual data entry and document verification, speed up claim processing to increase efficiency and accuracy and minimize errors and fraud. This removes the need to fetch documents, reducing errors and the time interval between the loss and claim filing.
Take, for instance, omnichannel call centers or document processing. Look for responsive support channels and resources such as documentation, tutorials, and training materials. Automate document processing with Nanonets Document processing is a common task in many BPOs. What are BPO automation software?
It is almost as old as the web and has many usecases that help run applications ranging from common daily use, such as the search engine, to cutting-edge modern applications like training LLMs that power AI. Scrape webpage now Usecases for web scraping Web scraping has many usecases across teams and industries.
OCR is widely used in various industries, including finance, healthcare, legal, government, and education, for various tasks such as document processing, data entry, and record-keeping. We can recognize a wide range of fonts, styles, and languages, making it a versatile tool for converting physical documents into digital format.
The API uses complex XML payloads and has strict formatting, so while it might initially seem nice to have a high level of detail in every API call, it can quickly become cumbersome for cases where you need to integrate the APIs at some level of scale. <soapenv:Envelope With SOAP, you need to create a RESTlet to use SuiteQL.
Want to scrape data from PDF documents, convert PDF to XML or automate table extraction ? Rather than relying on outdated methods like binders full of documents or emails, teams can use an automated system to document and share everything from how to complete a task to how that task fits into the overall organizational strategy.
The OCR has high accuracy and can handle many document formats and file sizes. Multiple OCRs exist for specific business usecases, including Invoice OCR and Receipt OCR. To get started, sign up for a Nanonets account and upload your document or PDF file. It comes with a lot of in-built features for the specific usecase.
While Sensible offers robust document processing capabilities, it’s not always the best fit for every business. While Sensible is a strong contender in the document processing space, it has limitations. 2 Nanonets Customizable workflows with complex unstructured documents Medium to large businesses 4.8
In this guide, we’ll dive into the specifics of the NetSuite REST API, including its setup , features , and usecases , while exploring advanced querying with SuiteQL , and how tools like Nanonets can scale your NetSuite-driven workflows. There are a few advantages due to which many developers prefer the REST API for NetSuite.
Healthcare data extraction systems capture and extract crucial information from a variety of healthcare documents—patient records, insurance forms, lab results, billing information, regulatory compliance documents, and more. million new frontline healthcare workers due to inefficient data extraction from healthcare documents.
While its free mobile app and API integration make it flexible for many users, its limitations, such as a 15-page processing cap and strict API rate limits, can hinder large scale document processing. For businesses needing more flexible, advanced document processing solutions, exploring alternatives to Veryfi is essential.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content