
Top 7 Sensible alternatives for document processing
Nanonets
NOVEMBER 19, 2024
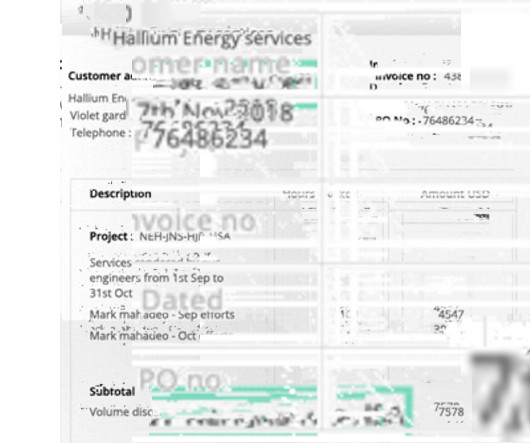
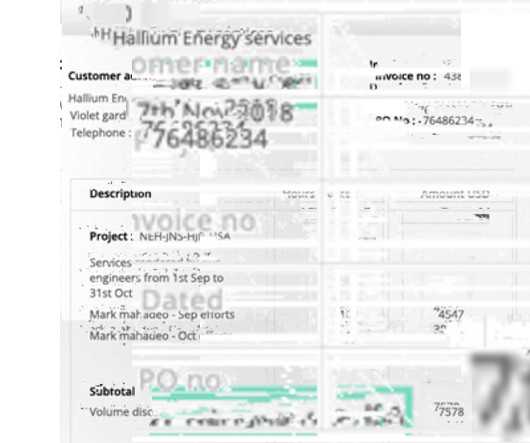
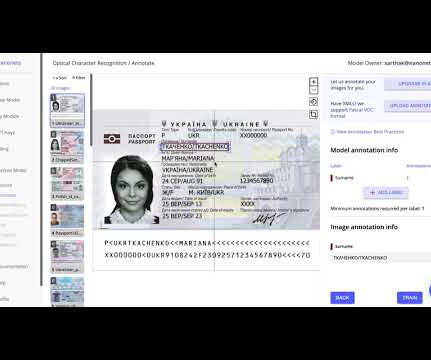
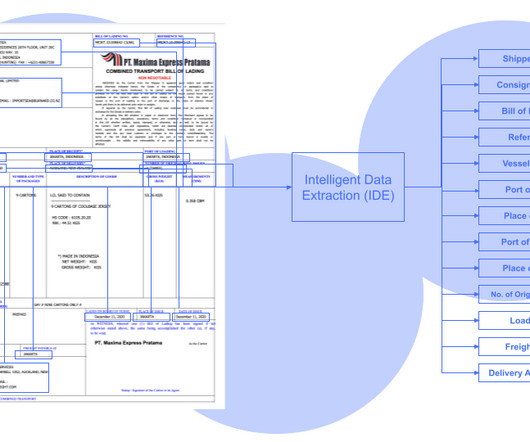
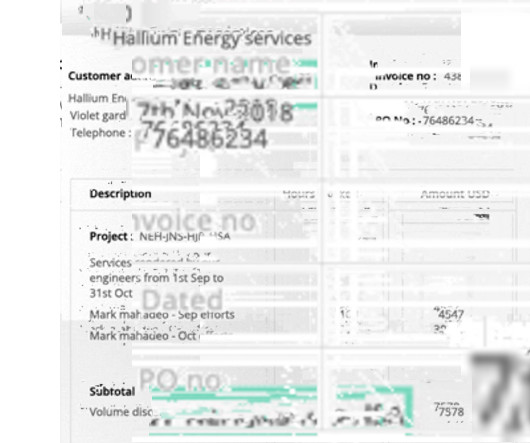
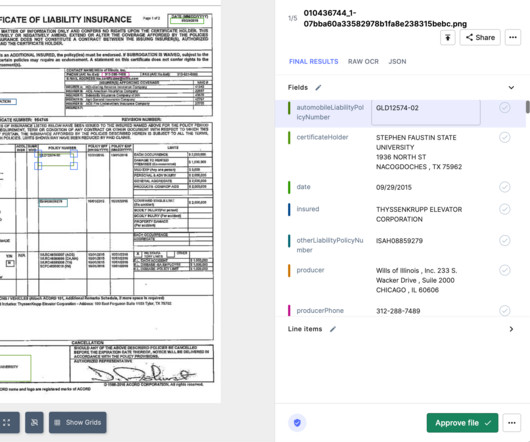
While Sensible offers robust document processing capabilities, it’s not always the best fit for every business. While Sensible is a strong contender in the document processing space, it has limitations. 2 Nanonets Customizable workflows with complex unstructured documents Medium to large businesses 4.8

































Let's personalize your content